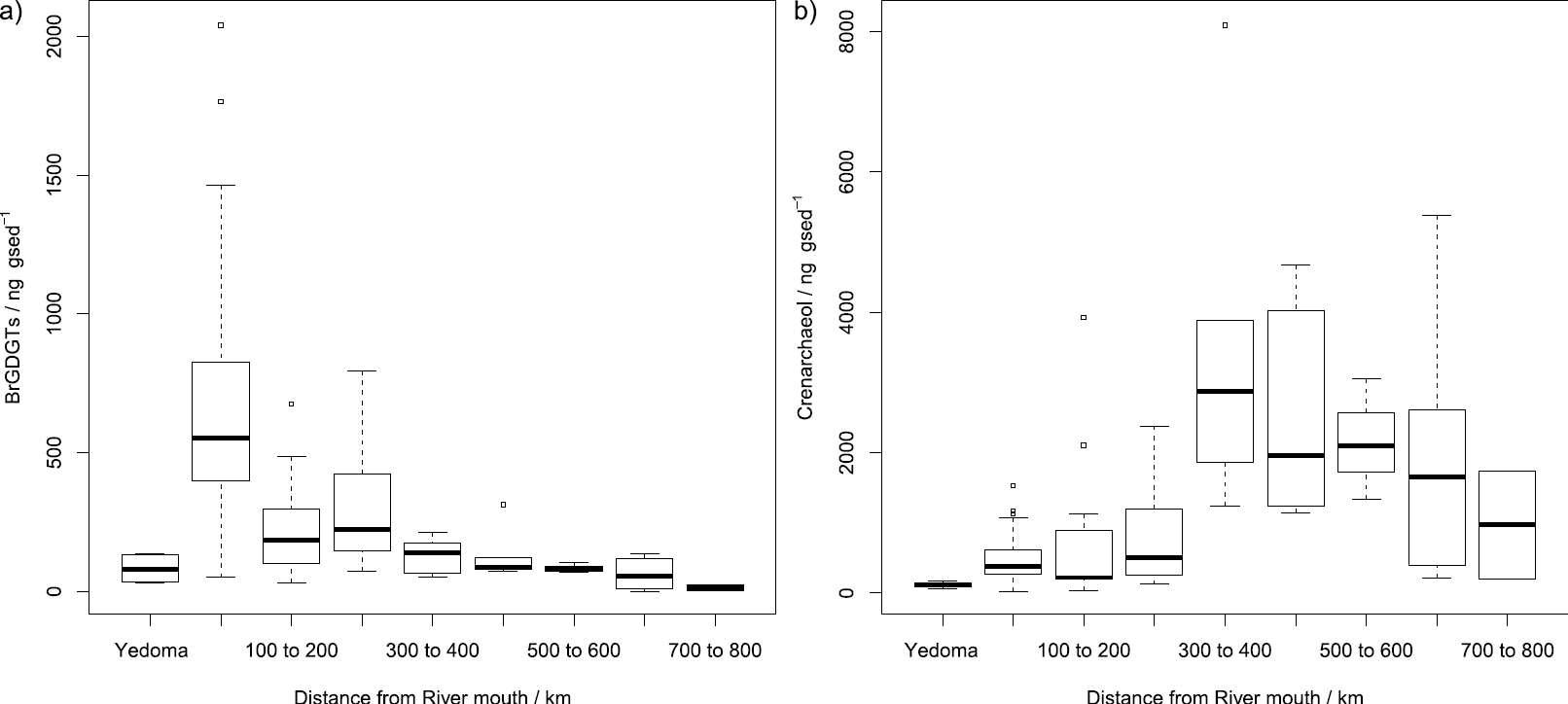
This paper, with Jens Turowski and Bob Hilton, was recently published as an open-access article in Geology and is available from the journal website and via the MMU e-space repository. In it we show that erosion and transport of large woody material (coarse particulate organic carbon; CPOC) is very important in terms of the overall carbon cycle, but is concentrated in very extreme events.
The research is based in the Erlenbach, a small river in the Alps that has been studied by Swiss researchers for several years. They have built a very sophisticated stream sampling station, which can capture everything that flows down past a gauging station. There is a large retention pond that catches the logs/pebbles/sediments and a shopping-trolley sized wire basket that can be moved into the middle of the stream to catch a particular time point (for example the middle of a large storm). The photo below was taken during winter when the river was frozen over, but you can see the v-shaped river channel, the three wire baskets ready to move into position to catch material, and the snow in the foreground covering the retention pond.

This sampling system led to Jens observing that there was a lot of CPOC coming down the river and piling up in the retention pond. A quick calculation suggested that this was a significant portion of the total carbon coming out of the river catchment, but the scientific consensus was that actually more carbon came through as fine particles than CPOC. An experiment was designed to test this.
Across a wide range of river flow speeds, the amount and size of woody debris flowing down the river was measured, both waterlogged and dry material. This allowed a rating curve to be defined – that is for a given river flow speed, how much organic carbon would be expected to flow down the river? The rating curve was very biased towards the high-flow end for CPOC, much more so than for fine carbon (FPOC) or dissolved carbon (DOC). At low flow rates, very little CPOC is moved, but at high flow rates a very large amount is mobilised.
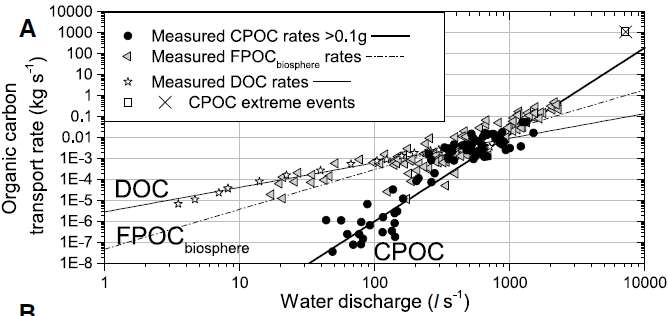
During the 31 years of data collection there were four particularly large storms. Integrating over the rating curve shows two things. Firstly, if the large storms are ignored then the Erlenbach is already a major source of CPOC, about 35% of the total carbon, with CPOC being roughly equal to the FPOC estimate. Thus it is much more important than might previously have been imagined. If the extreme events are included, the CPOC becomes ~80% of the total organic carbon transported by the river.
A majority of the CPOC transported by the river was waterlogged, having sat on the river bank or behind a log jam while waiting for a large storm to wash it downstream. Waterlogging increases the density of the wood and makes it more likely to sink when it reaches a lake or the sea. My contribution to the paper was to provide evidence of this process. My PhD work in the Italian Apennines found CPOC, from millimetre scale up to large tree trunks, that had been preserved in ocean sediments for millions of years. Again, a lot of this CPOC is too large to measure using standard techniques, and suggests that rivers can deliver organic carbon from mountains to the ocean far more efficiently than previously thought.